12ストアドプロシージャを使いこなす(備忘録)→ > 01p > 02p > 03p > 04p > 05p > END
12ストアドプロシージャを使いこなす(p256)
(1)ストアドプロシージャとはp256
(2)ストアドプロシージャを使う
(3)ストアドプロシージャの内容を表示・削除する p264
(4)ストアドファンクションとは
(5)ストアドファンクションを使うp266
(6)《トリガとは p273》
(7)《トリガを作成する p000》
(8)《トリガの確認・削除 p279》
<まとめ>
<チェック>
<練習問題>
END
12 ストアドプロシージャを使いこなす
単純にINSERT、SELECT、DELETEするだけでデータベースが運用できるわけではありません。実践では複雑に絡み合った複数のテーブルを使って大量のデータを扱い、処理の効率を考え、そして不慮のデータ消滅も許されません。MySQLの勉強も佳境を迎えています。条件を設定した抽出、編集から、リレーショナルの名にふさわしい複数のテーブルの利用。そして「ビュー」「ストアドプロシージャ」「トランザクション」「ファイル操作」という、より実践的で必要とされる内容を解説します。
☆CHAPTER08⇒いろんな条件で抽出する
☆CHAPTER09⇒テーブルを編集する
☆CHAPTER10⇒複数のテーブルを利用する
☆CHAPTER11⇒ビューを使いこなす
★CHAPTER12⇒ストアドプロシージャを使いこなす
☆CHAPTER13⇒トランザクションを使いこなす
☆CHAPTER14⇒ファイルを使ったやり取り
★CHAPTER12⇒ストアドプロシージャを使いこなす(p256)★
ストアドプロシージャを使うと、一連の手順を記録し、まとめて実行することができます。ストアドプロシージャは「同じ手順を毎回毎回繰り返して実行している」「一連の操作をまとめて記録し、忘れないようにしたい」というときの対応として便利です。「同じSQLコマンドを何回も実行しているような・・・・」と思ったら、その処理を「ストアドプロシージャ」にしておきましよう。「CALL XX」というコマンドを使うだけで、定義した処理をすぐに実行できます。
(1)ストアドプロシージャとはp256
(1-1)利用可能なバージョン
ストアドプロシージャは、バージョン5.0以降に対応しています。
(1-2)ストアドプロシージャとは何か
いくつものSQL文を1つにまとめ、それを「CALL ××」というコマンドだけで実行できるようにしたものをストアドプロシージャ(Stord Procedure)は「手順」といった意味です。 「ストアド」(Stored)は「貯蔵した」、「プロシージャ」(Procedure)は「手順」といった意味です。 つまり、ストアドプロシージャは「一連の手順を貯め込んでまとめたもの」です。 ※あらかじめ用意しておいた多くのコマンドを自動的に実行できるので、作業を効率的に行なうことができます。 ただし、「重要ななデータが蓄積されたデータベースで、よく検証されていないストアドプロシージャを実行するのは危険である」ということは、覚えておく必要があるでしょう。
●図12-1ストアドプロシージャ
 【図12-1ストアドプロシージャ⇒省略】
【図12-1ストアドプロシージャ⇒省略】※いっけん難解に感じるストアドプロシージャですが、一度使い方を覚えてしまえばとても便利です。例えば、「3回SELECT文を打つのが面倒だから、1回のCALLで済ませる」といったレベルでも気軽に利用できます。 次は、ここの例として作成するストアドプロシージャの本体です。 SELECT * FROM tb; SELECT * FROM tb1; 何の変哲もない普通のSQL文を、2個並べたものです。この例は2つだけのSQL文で構成されていますが、何個書き連ねてもかまいません。また、変数を使った「IF」や「CASE」で条件分岐したり、「WHERE」や「REPEAT」で繰り返し処理をする。といったプログラム言語ではお馴染みの処理もできます。 |
(2)ストアドプロシージャを使う
(2-1)ストアドプロシージャの作成
ストアドプロシージャを作成する場合、次のようなCREATE PROCEDUREというコマンドを実行します。
●書式⇒ストアドプロシージャを作成する
|
CREATE PROCDURE ストアドプロシージャ名() BEGIN SQL文1 SQL文2 END ※BEGINからENDまでが、ストアドプロシージャの本体となります。 最初に「BEGIN」を、最後に「END」を付けつことで、「ここからここまでのは範囲がストアドプロシージャのコマンド」だということを明らかにしています。 ストアドプロシージャの中身は、「普通のSQL文」です。ですから当然、コマンドの最後には、デリミタ「;」をつける必要があります。 つまり、前ページで紹介したストアドプロシージャを作る場合、本体部分は次のように記述します。 BEGIN SELECT * FROM tb; SELECT * FROM tb1; END ※ところがこのままでは、ストアドプロシージャを作っている最中にデリミタを入力することになっています。この場合、ストアドプロシージャが未完成の状態で「CREATE PROCEDURE」コマンドが実行されてしまうことになります。MySQLモニタはデリミタが入力されれば、どんな内容であろうと、取り敢えずそこまでの部分を実行してしまうのです。 |
●デリミタの設定を変更する
| 未入力の状態で実行されるのは困ります。記述の最後に「END」を入力した後に、「CREATE PROCEDURE」コマンドを実行するように環境を変更する必要があります。そこでストアドプロシージャを作成するときには、あらかじめデリミタの設定を「;」から別のものに変えておきます。一般的には「//」を使います。 |
●書式⇒デリミタを「//」に変更する
|
DELIMITER // ※デリミタを「//」にしておけば、ストアドプロシージャを作っている途中で「;」を入力しても問題ありません。そして「END」の後に「//」を入力時点で、「CREATE PROCEDURE」コマンドが実行されます。もちろん、ストアドプロシージャの作成が終了したら、「DELIMITER:」でデリミタをもとの設定に戻しておいてください。では、実際にやってみることにしましょう。 「SELECT * FROM tb;」 「SELECT * FROM tb1」 の2行を実行するストアドプロシージャ「pr1」を作成します。 |
●実行される結果(p259)
CALL pr1;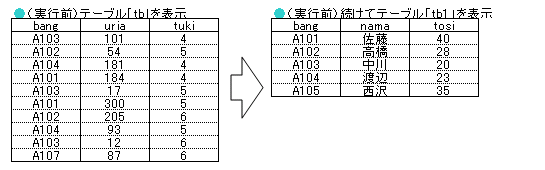
|
●操作手順
|
①次を実行する DELIMITER // CREATE PROCEDURE pr1() BEGIN SELECT * FROM tb; SELECT * FROM tb1; END // DELIMITER; |
□【実行結果】
|
mysql> DELIMITER // mysql> CREATE PROCEDURE pr1() -> BEGIN -> SELECT * FROM tb; -> SELECT * FROM tb1; -> END -> // Query OK, 0 rows affected (0.26 sec) mysql> DELIMITER; ※最後の「DELIMITER;」は区切り文字を元の「;」に戻すコマンドです。 デリミタを戻すのは忘れないで下さい。 また、ストアドプロシージャ名の後には、必ず()を付けてください。後でストアドプロシージャに引数として値を入れる例を紹介しますが、値を入れなくても()は付けなければいけません。 |
(2-2)ストアドプロシージャの実行
さて、これでストアドプロシージャ「pr1」が生成されました。では、これを使ってみます。 ストアドプロシージャを実行するのはCALLというコマンドです。
●書式⇒ストアドプロシージャの実行
|
CALL ストアドプロシージャ名; ※前項で作成した「pr1」を呼び出します。 CALL pr1; |
□【実行結果】
|
mysql> DELIMITER ; mysql> CALL pr1; +--------+------+------+ | bang | uria | tuki | +--------+------+------+ | A103 | 101 | 4 | | A102 | 54 | 5 | | A104 | 181 | 4 | | A101 | 184 | 4 | | A103 | 17 | 5 | | A101 | 300 | 5 | | A102 | 205 | 6 | | A104 | 93 | 5 | | A103 | 12 | 6 | | A107 | 87 | 6 | | 意地悪 | 50 | NULL | +--------+------+------+ 11 rows in set (0.25 sec) +------+------+------+ | bang | nama | tosi | +------+------+------+ | A101 | 佐藤 | 40 | | A102 | 高橋 | 28 | | A103 | 中川 | 20 | | A104 | 渡辺 | 23 | | A105 | 西沢 | 35 | +------+------+------+ 5 rows in set (0.34 sec) Query OK, 0 rows affected (0.34 sec) mysql> ※無事「SELECT * FROM tb;」「SELECT * FROM tb1;」の2行が連続で実行されました。 |
(2-3)指定した値以上のレコードだけ表示するストアドプロシージャを作るp261
次に、引数を指定して実行するストアドプロシージャを作ってみます。 処理して欲しいデータ()の引数に指定して、ストアドプロシージャを実行します。 ストアドプロシージャでは、次のような引数を記述します。
●書式⇒ストアドプロシージャの引数の記述
|
PROCEDURE ストアドプロシージャ名(引数名 データ型); ※ここでは簡単に、「指定した値以上の売上を持つレコードを表示」という、基本的なストアドプロシージャを作ってみることにします。 例えば、プロシージャ「pr」で整数型の引数「d」は、普通の数値と同じ様にSQL文の記述します。 例えば、次の処理を実行する場合、 テーブル「tb」で「uria」が、引数「d」以上のレコードを表示 次のように記述する SELECT * FROM tb WHERE uria>=d; それでは、テーブル「tb」で整数型の引数「d」の値を指定して実行すると、売上「uria」が「d」以上のレコードだけを表示するストアドプロシージャ「pr2」を作成してみよう。 |
●実行される結果(p262)
pr2(200)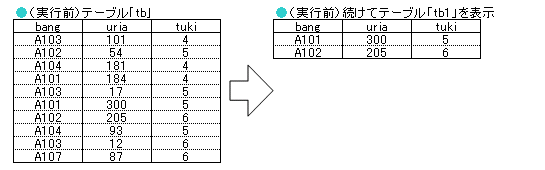
|
●操作手順
|
①次を実行する DELIMITER // CREATE PROCEDURE pr2(d INT) BEGIN SELECT * FROM tb WHERE uria>=d; END // DELIMITER; |
□【実行結果】
|
mysql> DELIMITER // mysql> CREATE PROCEDURE pr2(d INT) -> BEGIN -> SELECT * FROM tb WHERE uria>=d; -> END -> // Query OK, 0 rows affected (0.47 sec) mysql> DELIMITER; ※では、引数に「200」の数値を指定してプロシージャ「pr2」を実行してみることにしましょう。()内に200を記述してCALLを実行します。 CALL pr2(200); |
□【実行結果】
|
mysql> CALL pr2(200); +------+------+------+ | bang | uria | tuki | +------+------+------+ | A101 | 300 | 5 | | A102 | 205 | 6 | +------+------+------+ 2 rows in set (0.00 sec) Query OK, 0 rows affected (0.00 sec) mysql> ※「200」以上の売上を持つレコードだけが表示されました。 |
(3)ストアドプロシージャの内容を表示・削除する p264
ストアドプロシージャの内容を表示する方法、そして削除する方法です。
(3-1)ストアドプロシージャの内容を表示
作ったストアドプロシージャの内容を表示するときに、次を実行します。
●書式⇒ストアドプロシージャの内容を表示する
|
SHOW CREATE PROCEDURE プロシージャ名; ※例えば、次では、ストアドプロシージャ「pr2」の内容を表示しています。 |
□【実行結果】
|
mysql> SHOW CREATE PROCEDURE pr2;
+-----------+----------+--------------------------------------------------------
---------------------------------------------+ | Procedure | sql_mode | Create Procedure | +-----------+----------+-------------------------------------------------------- ---------------------------------------------+ | pr2 | | CREATE DEFINER=`root`@`localhost` PROCEDURE `pr2`(d INT ) BEGIN SELECT * FROM tb WHERE uria>=d; END | +-----------+----------+-------------------------------------------------------- ---------------------------------------------+ 1 row in set (0.00 sec) mysql> ※(ストアドプロシージャ「pr2」の内容を表示) |
(3-2)ストアドプロシージャの削除 p264
ストアドプロシージャを削除する場合には、データベースやテーブル、ビューに対するのと同じ「DROP」コマンドを使います。
●書式⇒ストアドプロシージャを削除する
|
DROP PROCEDURE ストアドプロシージャ名; mysql> DROP PROCEDURE pr2; Query OK, 0 rows affected (0.00 sec) mysql> |
(4)ストアドファンクションとは
(4-1)利用可能なバージョン
MySQLのバージョン5.0以降に対応しています。
(4-2)ストアドファンクションとは何か
ストアドプロシージャの考え方や操作方法は、ほとんどストアドプロシージャと同じです。 ストアドプロシージャと唯一違うのは、「実行したときに値を返す」という点です。 ファンクション(FUNCTION)とは、「関数」という意味です。ストアドプロシージャは、その名の通り、関数として働きます。MySQLにはいろいろな関数があることを説明しましたが、ストアドプロシージャを使えばオリジナル関数を作ることもできます。ストアドプロシージャは、ユーザー関数と呼ばれることもあります。
●図12-2ストアドファンクション
|
【詳細図省略12-2ストアドファンクション】 ※ストアドファンクションで返された値は、「SELECT」「UPDATE」などのコマンドで、通常の関数と同じ様に利用できます。 次の構文で、ストアドファンクションを作成します。 |
●書式⇒ストアドファンクションを作成する
|
CREATE FUNCTION ストアドファンクション名(引数 データ型) RETURNS 返す値のデータ型 BEGIN SQL文・・・ RETURN 返す値・式 END ※ストアドプロシージャと同じように、()内に引数を指定することができます。 また、例えば、引数を指定しなくても()を付けなくてはなりません。 |
(5)ストアドファンクションを使うp266
(5-1)ストアドファンクションで標準体重を計算する
「BMI=22」が標準体重という考え方を使うと、次の式が成り立ちます。
標準体重=身長(cm単位)×身長(cm単位)×22/10000
これを使ってストアドファンクション「fu1」を作ってみることにしましょう。
ここでは引数として、cm単位の身長の値を「sintyo」の名前で、整数型で指定してみることにしましょう。ストアドファンクション「fu1」で、INT型の引数を指定する場合、次のようになります。
CREATE FUNCTION fu1(sintyo INT)
ストアドファンクションは、それ自体が値を返します。そのため、このストアドファンクション自体が返す値のデータ型を指定する必要があります。今回は「fu1」が返すのは、小数点以下も含む標準体重です。そこで、「fu1」が返す値には小数点以下も扱える「DOUBLE」型を指定。結果、次のようになります。
CREATE FUNCTION fu1(sintyo INT) RETURNS DOUBLE
では、オリジナルの標準体重処理関数を作ってみましょう。
●実行される結果
|
SELECT fu1(174);#引数に身長174cmを指定すると・・・ ↓ 174×174×22/10000を計算#BMI値を22で計算 66.6072…(計算した値)を返す#標準体重を返す。 |
●操作手順
|
①次を実行する DELIMITER // CREATE FUNCTION fu1(sintyo INT) RETURNS DOUBLE BEGIN RETURN sintyo * sintyo * 22/10000; END // DELIMITER ; |
●実行結果
|
mysql> DELIMITER // mysql> CREATE FUNCTION fu1(sintyo INT) RETURNS DOUBLE -> BEGIN -> RETURN sintyo * sintyo * 22/10000; -> END -> // Query OK, 0 rows affected (0.01 sec) mysql> DELIMITER ; ※では、身長174cmで計算して見ることにしましょう。 今度は「fu1()」が関数として、値を返します。そのため、「CALL」を使うのではなく「SELECT」コマンドで「fu1()」の値を表示することになります。「()」内に入れる引数の値は「174」です。 SELECT fu1(174); |
●実行結果
|
mysql> SELECT fu1(174); +----------+ | fu1(174) | +----------+ | 66.6072 | +----------+ 1 row in set (0.44 sec) mysql> |
(5-2)<レコードの平均値を返すストアドファンクションp269>
特定のテーブル・カラムの平均値を返す関数、つまりストアドファンクションを作ってみることにしましょう。こんな関数でもあらかじめ作っておくと、けっこう便利に使えるものです。最初に、完成したストアドファンクションを示します。テーブル「tb」のカラム「uria」の平均値を返すストアドファンクション「fu2」を作成するための記述です。
CREATE FUNCTION fu2() RETURNS DOUBLE →①
BEGIN
DECLARE r DOUBLE;→②
SELECT AVG(uria) INTO r FROM tb;→③
RETURN r;→④
END
①の部分は、前ページと同様で、ストアドファンクション「fu2」の全体を返す値をDOUBLE型としました。
CREATE FUNCTION fu2() RETURUNS DOUBLE
さて、平均はAVG関数を使って「SELECT AVG()」で求めます。この値は一度、変数に代入しておかなければなりません。変数というのは「値を保管する箱」のことです。変数を使うためには、あらかじめDECLAREで次のように定義します。
●書式⇒DECLAREによる変数の定義
|
DECLARE 変数名 テーブル型 ※ここでは、平均を入れる変数名を「r」としました。変数「r」には、平均が入ります。このため小数点以下の数値を扱えるように、テーブル型をDOUBLE型で指定することにします。「r」という変数をDOUBLE型で定義するのが、 次の②です。 DECLARE r DOUBLE; テーブル「tb」のカラム「uria」の平均を取り出すSQL文は、次の様になります。 SELECT AVG(uria) FROM tb; このAVG(uria)をDECLAREで定義した変数「r」に代入するときは、「INTO」を使います。結局 次の③のようになります。 SELECT AVG(uria) INTO r FROM tb; これで変数「r」に平均値が代入されるので、 これを④の「RETURN」でストアドファンクションの値として返すことが出来るのです。 RETURNY; ※実際にやって見ましょう。テーブル「tb」のカラム「uria」の平均を「DOUBLE」型の値として返すストアドファンクション「fu2」を作ってみましょう。 |
●実行される内容
SELECT fu2();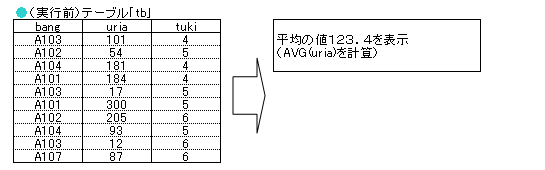
|
●実行される内容
|
DELIMITER // CREATE FUNCTION fu2() RETURNS DOUBLE BEGIN DECLARE r DOUBLE; SELECT AVG(uria) INTO r FROM tb; RETURN r; END // DELIMITER ; |
■実行結果
|
mysql> SELECT * FROM tb; +--------+------+------+ | bang | uria | tuki | +--------+------+------+ | A103 | 101 | 4 | | A102 | 54 | 5 | | A104 | 181 | 4 | | A101 | 184 | 4 | | A103 | 17 | 5 | | A101 | 300 | 5 | | A102 | 205 | 6 | | A104 | 93 | 5 | | A103 | 12 | 6 | | A107 | 87 | 6 | | 意地悪 | 50 | NULL | +--------+------+------+ 11 rows in set (0.01 sec) mysql> DELIMITER // mysql> CREATE FUNCTION fu2() RETURNS DOUBLE -> BEGIN -> DECLARE r DOUBLE; -> SELECT AVG(uria) INTO r FROM tb; -> RETURN r; -> END -> // Query OK, 0 rows affected (0.44 sec) mysql> DELIMITER ; mysql> SELECT fu2(); +---------------+ | fu2() | +---------------+ | 116.727272727 | +---------------+ 1 row in set (0.36 sec) |
(5-3)<ストアドファンクションの内容を表示・削除するp272>
ストアドファンクションの内容を表示したり、削除したりする方法はストアドプロシージャと同じです。
●書式⇒ストアドファンクションの削除
|
mysql> SHOW CREATE FUNCTION fu2; +----------+----------+--------------------------------------------------------- -------------------------------------------------------------------------------- -+ | Function | sql_mode | Create Function | +----------+----------+--------------------------------------------------------- -+ | fu2 | | CREATE DEFINER=`root`@`localhost` FUNCTION `fu2`() RETUR NS double BEGIN DECLARE r DOUBLE; SELECT AVG(uria) INTO r FROM tb; RETURN r; END | +----------+----------+--------------------------------------------------------- -+ 1 row in set (0.00 sec) mysql> DROP FUNCTION ストアドファンクション名; mysql> DROP FUNCTION fu2; Query OK, 0 rows affected (0.35 sec) mysql> SHOW CREATE FUNCTION fu2; ERROR 1305 (42000): FUNCTION fu2 does not exist mysql> |
●書式⇒ストアドファンクションの内容表示
| SHOW CREATE FUNCTION ファンクション名; |
●実行結果
|
mysql> SHOW CREATE FUNCTION fu2; +----------+----------+--------------------------------------------------------- -+ | Function | sql_mode | Create Function | +----------+----------+--------------------------------------------------------- -+ | fu2 | | CREATE DEFINER=`root`@`localhost` FUNCTION `fu2`() RETUR NS double BEGIN DECLARE r DOUBLE; SELECT AVG(uria) INTO r FROM tb; RETURN r; END | +----------+----------+--------------------------------------------------------- -+ 1 row in set (0.00 sec) mysql> DROP FUNCTION fu2; Query OK, 0 rows affected (0.35 sec) mysql> SHOW CREATE FUNCTION fu2; ERROR 1305 (42000): FUNCTION fu2 does not exist mysql> |
(6)《トリガとは p273》
(6-1)<利用可能なバージョン>
MySQLのバージョン5.0以降に対応しています。
(6-2)<トリガとは何か p273>
トリガは、テーブルに対してある処理が行なわれると、それが引き金(トリガ:trigger)となってコマンドが実行される仕組みです。 「INSERT」「UPDATE」「DELETE」などのコマンドが実行されるとき、あらかじめトリガとして設定しておいた機能も実行させることができます。たとえば、あるテーブルのレコードを「更新する」という処理が起こると、それをきっかけにして「変更を別のテーブルに記録する」仕組みをトリガで作ることができます。 ※トリガは、処理の結果や、万が一処理を失敗したときの保険としても活躍します。
●図12-3トリガ
|
【図12-3トリガは省略】 ※トリガは強力な機能なのですが、説明を聞いただけでは何がメリットで何がすごいのかよくわかりません。体験してみましょう。 ここでは、「テーブルにあるレコードを削除すると、削除したレコードが別のテーブルにコピーされる」というトリガを作って見ることにしましょう。 テーブル「tb1」に対して「DELETE FROM tb1…」のコマンドが実行されたら、これにより削除したレコードをいっでも復活できるようになります。 あらかじめ、テーブル「tb1」で削除したレコードを挿入する、空っぽのテーブル「tb1M」を作っておいてください。 テーブル「tb1」のカラム構造だけをコピーして作ります。 CREATE TABLE tb1M LIKE tb1; mysql> CREATE TABLE tb1M LIKE tb1; Query OK, 0 rows affected (0.23 sec) mysql> SELECT * FROM tb1M; Empty set (0.03 sec) mysql> |
(7)《トリガを作成する p000》
トリガはテーブルに対して「INSERT」「UPDATE」「DELETE」などのコマンドが実行される直前「BEFROE」、あるいは実行した直後「AFTER」に、呼び出されて実行します。
(7-1)<トリガが呼び出されるタイミング>
トリガが呼び出されるタイミングの指定は次の2つがあります。
●トリガが呼び出されるタイミング
|
BEFORE⇒テーブルに対する処理が行なわれる直前に呼び出される AFTER⇒テーブルに対する処理が行なわれない直後に呼び出される ※そして、テーブルに対する処理が行なわれる直前と直後の値は、次のように「OLD.カラム名」「NEW.カラム名」で得る事が出来る。 |
●カラムの値
|
OLD.カラム名⇒テーブルに対する処理が行なわれる直前の「カラム名」の値 AFTER.カラム名⇒テーブルに対する処理が行なわれた直後の「カラム名」の値 「INSERT」「UPDATE」「DELETE」のコマンドが実行される前のカラムの値を「OLD.カラム名」、実行した後のカラム名の値を「NEW.カラム名」として取り出せるわけです。 ただし、コマンドによって取り出されるものと取り出せないものがあります。次の表の中で、○が取り出されるものです。  画像 画像
|
(7-2)<トリガの作成>
実際に使ってみた方がよくわかります。トリガを作成するときは、次のようにします。
●書式⇒トリガの作成
|
CREATE TRIGGER トリガ名 BEFROE(あるいはAFTER) DELETE などのコマンド ON テーブル名 FOR EACH ROW BEGIN 更新(OLD.カラム名)または更新後(NEW.カラム名)を使った処理 END ※トリガの本体での記述では、各コマンドの最後に「;」を付けます。従って、ストアドプロシージャの時と同様に、あらかじめデリミタ「//」などに変更しておく必要があります。 では、前ページで紹介したトリガを作ってみよう。テーブル「tb1」のレコードを削除(DELETE)し、削除したレコードを「tb1M」に挿入するトリガ「tr1」を設定します。 |
●実行される内容
テーブル「tb1」で削除したレコードを「tb1M」に挿入するトリガ作成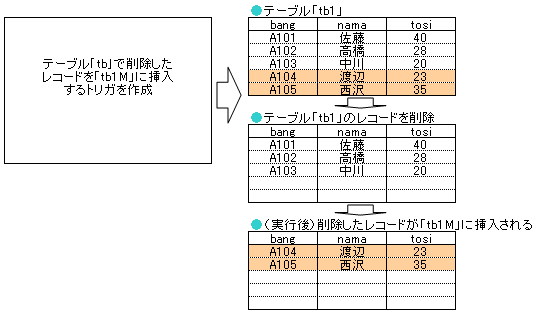 |
●操作手順
|
①次を実行する DELIMITER // CREATE TRIGGER tr1 BEFORE DELETE ON tb1 FOR EACH ROW BEGIN INSERT INTO tb1M VALUES(OLD.bang,OLD.nama,OLD.tosi); END // DELIMITER ; |
■実行結果
|
mysql> DELIMITER ; mysql> DELIMITER // mysql> CREATE TRIGGER tr1 BEFORE DELETE ON tb1 FOR EACH ROW -> BEGIN -> INSERT INTO tb1M VALUES(OLD.bang,OLD.nama,OLD.tosi); -> END -> // Query OK, 0 rows affected (0.10 sec) mysql> DELIMITER ; ※トリガが完成しました。この内容については、次項で解説します。とりあえず、トリガの働きを体験してみることにしましょう。 これで、テーブル「tb1」で削除したレコードは「tb1M」に挿入されるはずです。1レコードでも2レコードでも動作しますが、ここでは思い切ってレコード全部削除してみます。 DELETE FROM tb1; 一応、「SELECT *FROM tb1;」で本当に削除されたことを確認してみます。 |
■実行結果
|
mysql> DELETE FROM tb1; Query OK, 5 rows affected (0.52 sec) mysql> SELECT * FROM tb1; Empty set (0.00 sec) ※「Empty set」となり、何も表示されません。テーブル「tb1」にレコードは残っていません。 果たして、設定したトリガは動作しているでしょうか?では、テーブル「tb1M」を見てみましょう。 SELECT * FROM tb1M; |
■実行結果
|
mysql> SELECT * FROM tb1M; +------+------+------+ | bang | nama | tosi | +------+------+------+ | A101 | 佐藤 | 40 | | A102 | 高橋 | 28 | | A103 | 中川 | 20 | | A104 | 渡辺 | 23 | | A105 | 西沢 | 35 | +------+------+------+ 5 rows in set (0.00 sec) mysql> ※予定通り、削除したレコードが挿入されています(SELECTで表示される順番は変更することもあります)。 トリガが機能しました。もし動作しなかったときは、入力した履歴を確認してください。原因の多くはタイプミスです。 SHOWコマンドで内容を確認できます。 では、「tb1M」に挿入されたデータを、元の「tb1」に復活させましょう。 戻すときは、 INSERT INTO tb1 SELECT * FROM tb1M;とします。 mysql> INSERT INTO tb1 SELECT * FROM tb1M; Query OK, 5 rows affected (0.00 sec) Records: 5 Duplicates: 0 Warnings: 0 mysql> SELECT * FROM tb1; +------+------+------+ | bang | nama | tosi | +------+------+------+ | A105 | 西沢 | 35 | | A104 | 渡辺 | 23 | | A103 | 中川 | 20 | | A102 | 高橋 | 28 | | A101 | 佐藤 | 40 | +------+------+------+ 5 rows in set (0.00 sec) mysql> SELECT * FROM tb1M; +------+------+------+ | bang | nama | tosi | +------+------+------+ | A101 | 佐藤 | 40 | | A102 | 高橋 | 28 | | A103 | 中川 | 20 | | A104 | 渡辺 | 23 | | A105 | 西沢 | 35 | +------+------+------+ 5 rows in set (0.00 sec) mysql> |
(7-3)<作成したトリガの内容>
さて、作成したトリガの内容を見てみましょう。
|
DELIMITER // CREATE TRIGGER tr1 BEFORE DELETE tb1 FOR EACH ROW BEGIN INSERT INTO tb1M VALUES(OLD.bang,OLD.nama,OLD.tosi); END // DELIMITER; ※まず、テーブル「tb1」に対する「DELETE」コマンドを引き金にしたトリガ「tr1」を設定します。削除する直前(BEFORE)の値を「INSERT」するのですから、「CREATE TRIGGER」の部分は次のようになります。 CREATE TRIGGER tr1 BEFORE DELETE ON tb1 FOR EACH ROW レコードを削除する前(BERURE)の値(OLD.カラム名)を取り出し、これをテーブル「tb1M」に挿入します。 テーブル「tb1M」のカラムは「bang」「nama」「tosi」なので、それぞれ「OLD.bang」「OLD.nama」「OLD.tosi」が削除する直前のカラムの値になります。 これを「INSERT」コマンドでテーブル「tb1M」に挿入するので、トリガ本体の記述は次のようになります。 INSERT INTO tb1M VALUES(OLD.bang,OLD.nama,OLD.tosi); 後は、ストアドプロシージャと同様に、途中で「;」が使えるようにデリミタ「//」に変更(「DELIMITER//」)。 トリガの本体を「BEGIN」と「END」で囲み、最後にデリミタ「;」に戻しています(「DELIMITER;」)。 |
(8)《トリガの確認・削除 p279》
(8-1)<設定されているトリガの確認>
さて、作成したトリガの内容を見てみましょう。
|
トリガは自動的に起動するものです。意図しない処理が行なわれないよう、管理には十分機を使う必要があります。現在設定されているトリガとその内容は、常に把握しておきましょう。 現在設定されているトリガは、「SHOW TRIGGERS」コマンドで確認できます。 |
●書式⇒トリガの確認
| SHOW TRIGGERS; |
●実行結果
|
mysql> SHOW TRIGGERS; +---------+--------+-------+---------------------------------------------------- ------------+--------+---------+----------+----------------+ | Trigger | Event | Table | Statement | Timing | Created | sql_mode | Definer | +---------+--------+-------+---------------------------------------------------- ------------+--------+---------+----------+----------------+ | tr1 | DELETE | tb1 | BEGIN INSERT INTO tb1M VALUES(OLD.bang,OLD.nama,OLD.tosi); END | BEFORE | NULL | | root@localhost | +---------+--------+-------+---------------------------------------------------- ------------+--------+---------+----------+----------------+ 1 row in set (2.33 sec) mysql> |
(8-2)<トリガを削除>
意図しない処理が行なわれないように、必要ないトリガは削除しておきましょう。
●書式⇒トリガの削除
|
DROP TRIGGER トリガ名; ※トリガ「tr1」を削除してみましょう。次を実行して下さい。 DROP TRIGGER tr1; |
●実行結果
|
mysql> DROP TRIGGER tr1; Query OK, 0 rows affected (0.01 sec) mysql> ※これで、トリガ「tr1」が削除されます。削除されたことを「SHOW TRIGGERS;」で確認してみよう。 |
●実行結果
|
mysql> SHOW TRIGGERS; Empty set (0.03 sec) mysql> |
<まとめ>
●ストアドプロシージャの意味と作成方法
●ストアドファンクションの意味と作成方法
●引数を処理する方法
●トリガの意味と作成方法
●トリガによって取得できるカラムのデータ種類とタイミング
※「ストアドプロシージャは複数の処理をまとめて実行するもの」と学びました。サーバにおける処理をストアドプロシージャとしてまとめて行なえば、クライアントとサーバとのやり取りをそれだけ少なくすることができます。つまり、ストアドプロシージャを利用することで、処理全体を高速化できる可能性があるということです。また、処理をひとまとめにしておくことで、誤った手順を実行することを防ぐこともできます。
<チェック>
□「CREATE PROCEDURE」でストアドプロシージャを作成し、「CALL」で実行することができる。
□デリミタを自由に変更することができる
□引数を設定したストアドプロシージャが作成できる
□ストアドファンクションを作成することができる。
□SELECTで得た値を返す巣とアドファンクションをっ作ることができる
□「CREATE TRIGGER」でトリガを作成することができる。
□「BEFORE」「AFTER」により、実行前後のカラムの値を取り出すことができる
<練習問題>
問題1
次のテーブル「tb」を利用して、引数「t」(INT)として日(tuki)の4~6のどれかの値を指定すると、その月の売上(uria)の合計(INT)を返すストアドファンクション「f_uria」を作成して下さい。
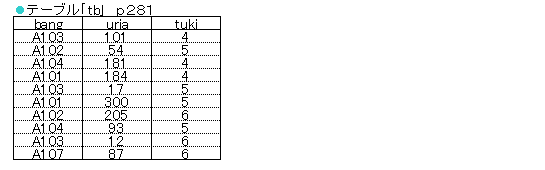
《解答1》
|
次を実行します DELIMITER // CREATE FUNCTION f_uria(t INT) RETURNS INT BEGIN DECLARE u INT; SELECT SUM(uria) INTO u FROM tb WHERE tuki=t; RETURN u; END // DELIMITER ; |
●実行結果
|
mysql> DELIMITER // mysql> CREATE FUNCTION f_uria(t INT) RETURNS INT -> BEGIN -> DECLARE u INT; -> SELECT SUM(uria) INTO u FROM tb WHERE tuki=t; -> RETURN u; -> END -> // Query OK, 0 rows affected (0.17 sec) mysql> DELIMITER ; mysql> SELECT f_uria(4); +-----------+ | f_uria(4) | +-----------+ | 466 | +-----------+ 1 row in set (0.14 sec) mysql> |